构建轻量级模型对齐系统:从RLHF到实时反馈与自我纠错
发布日期:2024年5月2日 | 阅读时间:15分钟
在当前大模型快速发展的时代,如何让AI更好地理解和服务人类需求,已成为技术社区的核心议题。一个行为符合人类价值观、能高效执行用户任务的AI系统,需要经过精心的模型对齐过程。本文将深入探讨基于RLHF、DPO和RLAIF的对齐技术,以及如何构建轻量级实时反馈与自我纠错机制,让AI更懂人心。
什么是模型对齐?
模型对齐(Model Alignment)是指调整AI系统的行为,使其与人类意图、价值观和期望保持一致的过程。一个良好对齐的AI系统能够:
- 生成符合人类期望的内容
- 拒绝生成有害、误导或不当内容
- 表现出更高的可靠性和可信度
- 在存在歧义时,合理解读用户的真实意图
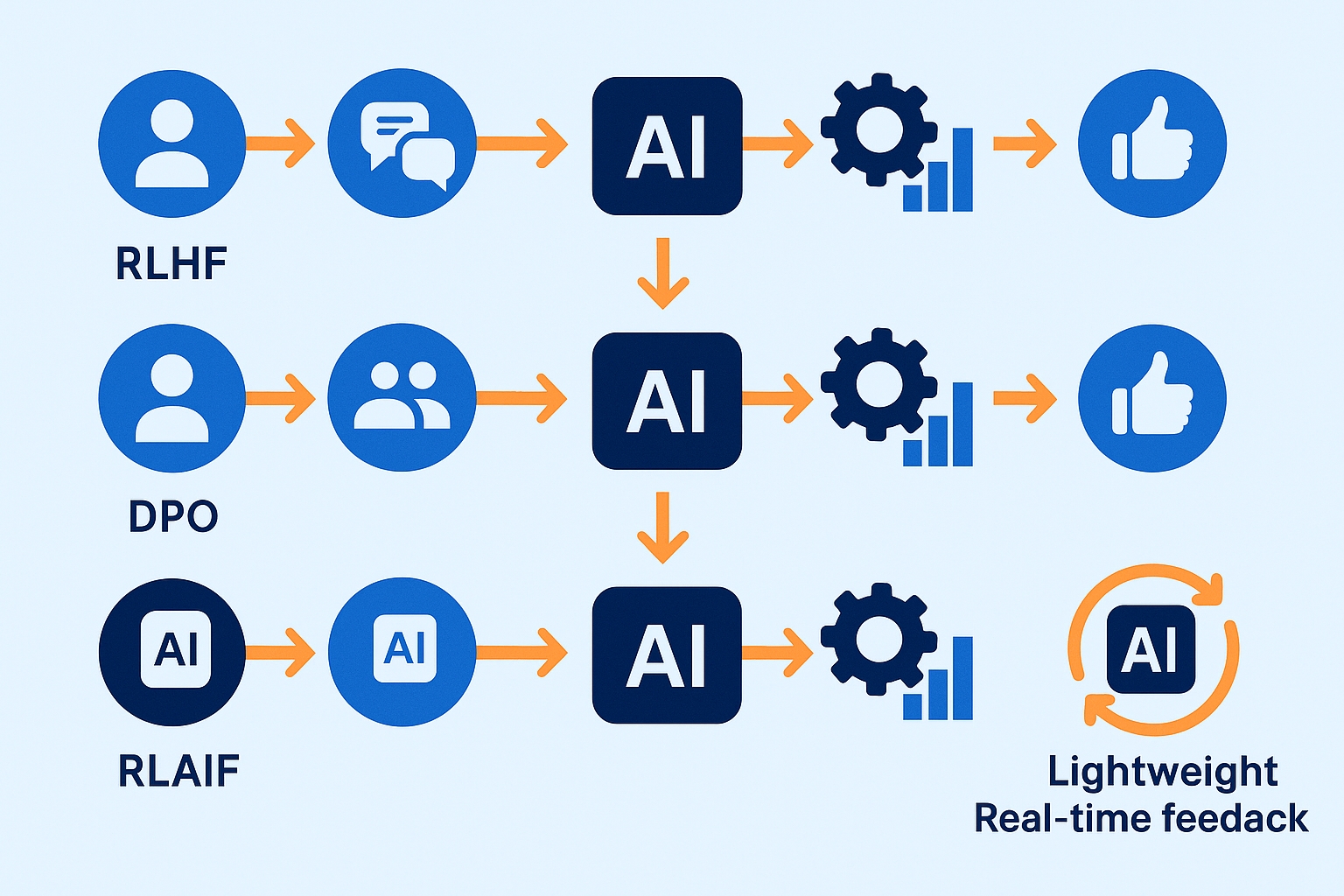
主流模型对齐技术剖析
1. RLHF(基于人类反馈的强化学习)
RLHF作为目前业界最成熟的对齐方法,已被OpenAI、Anthropic等头部公司广泛应用于GPT-4和Claude等产品。它通过引入人类偏好作为训练信号,使模型输出更符合人类期望。
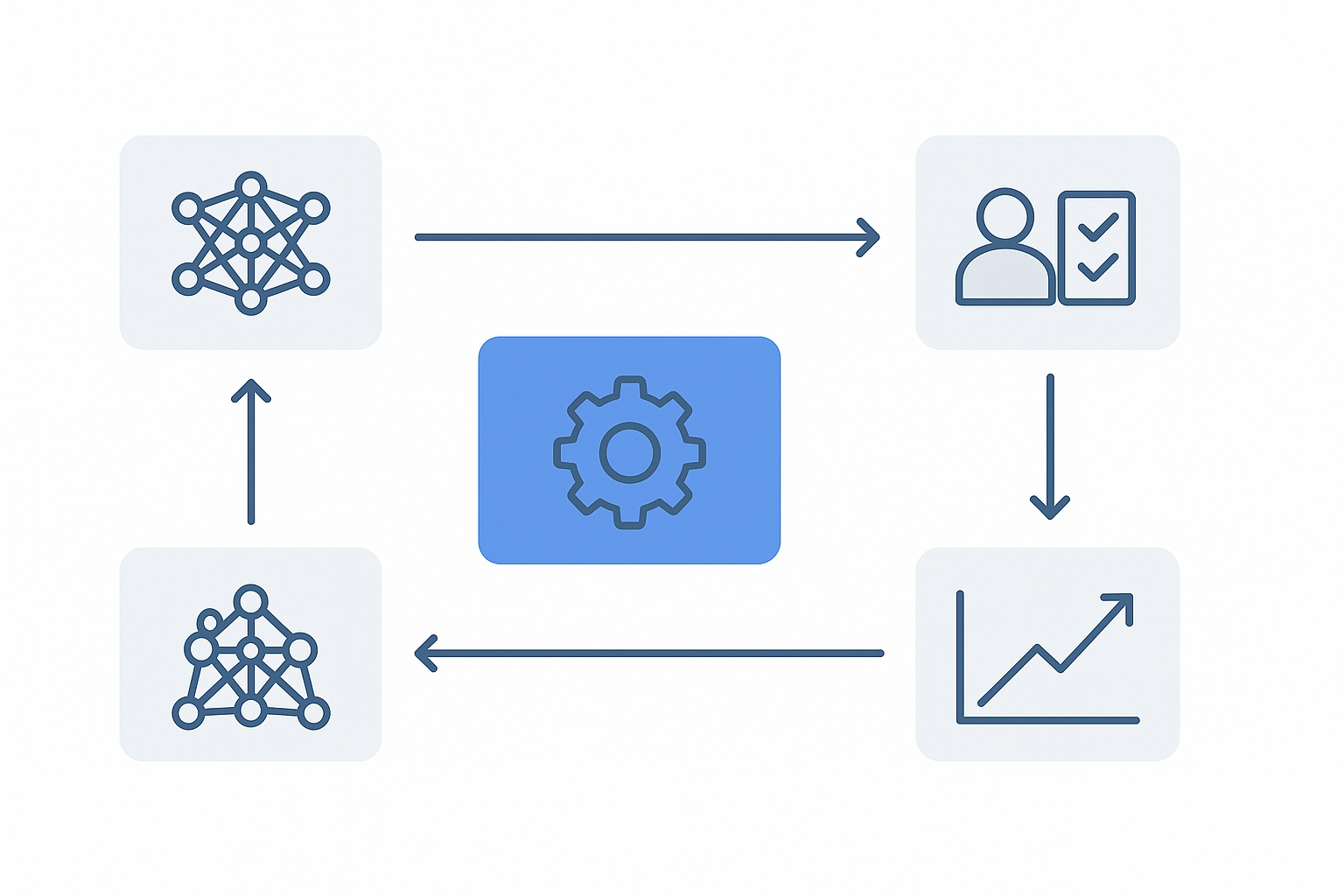
RLHF的核心工作流程包括三个阶段:
- SFT(监督微调):基于人类编写的示例对预训练模型进行初步调整
- 奖励模型训练:收集人类对模型回答的偏好标注,训练一个能预测人类偏好的奖励模型
- 策略优化:使用奖励模型和PPO等强化学习算法优化语言模型,使其生成更符合人类偏好的内容
个人实践笔记
在实际项目中实施RLHF时,我发现奖励模型的质量对最终效果影响巨大。一个建议是组建多样化的评分团队,确保收集到不同背景、专业领域的人类偏好数据。这样可以避免模型只贴合特定群体的价值观,而忽略了更广泛的社会共识。同时,设计合理的标注指南至关重要,比如将"有用性"和"无害性"分开评估,可以得到更精准的人类反馈信号。
2. DPO(直接偏好优化)
DPO是一种新兴的对齐方法,它简化了RLHF的复杂流程,无需显式地训练奖励模型,直接利用偏好对比数据优化模型策略。
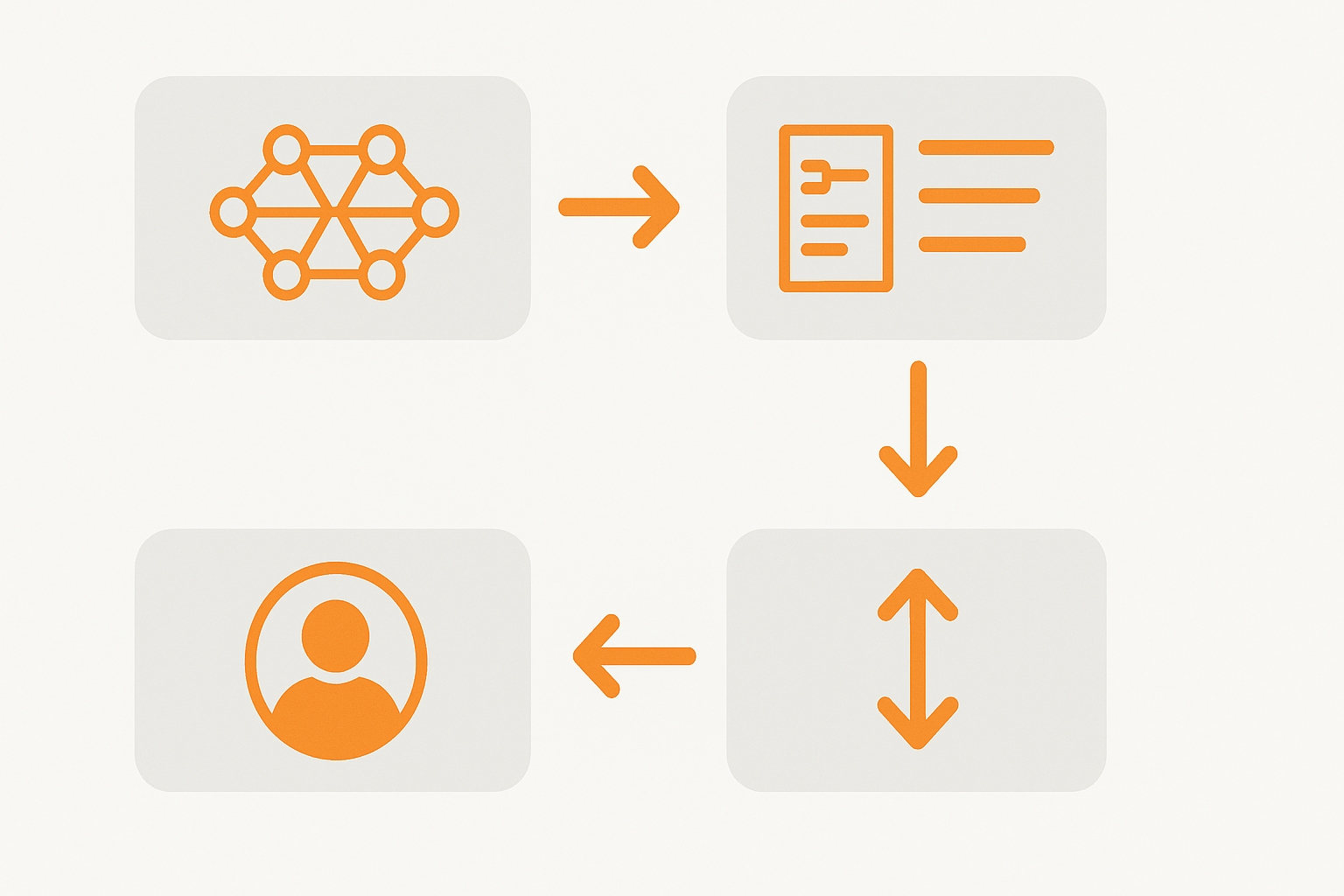
DPO的优化过程更加简洁:
- SFT(监督微调):与RLHF相同,首先进行基础的监督微调
- 偏好数据收集:收集成对的回答及人类对它们的偏好标注
- 直接优化:使用专门设计的损失函数,直接优化模型参数,使其输出更接近人类偏好的回答
def dpo_loss(model, preferred_outputs, rejected_outputs, prompts, beta=0.1):
# 计算偏好输出和拒绝输出的对数概率
preferred_logps = model.log_probs(prompts, preferred_outputs)
rejected_logps = model.log_probs(prompts, rejected_outputs)
# 计算偏好差异
logits = preferred_logps - rejected_logps
# 计算正则化项
reference_probs = reference_model.probs(prompts, preferred_outputs, rejected_outputs)
kl_penalty = kl_divergence(model.probs, reference_probs)
# DPO Loss
loss = -torch.log(torch.sigmoid(logits - beta * kl_penalty))
return loss.mean()3. RLAIF(基于AI反馈的强化学习)
RLAIF是解决人类标注成本高昂问题的创新对齐方法,它用大型语言模型替代人类来提供反馈,极大地提升了对齐过程的可扩展性和效率。
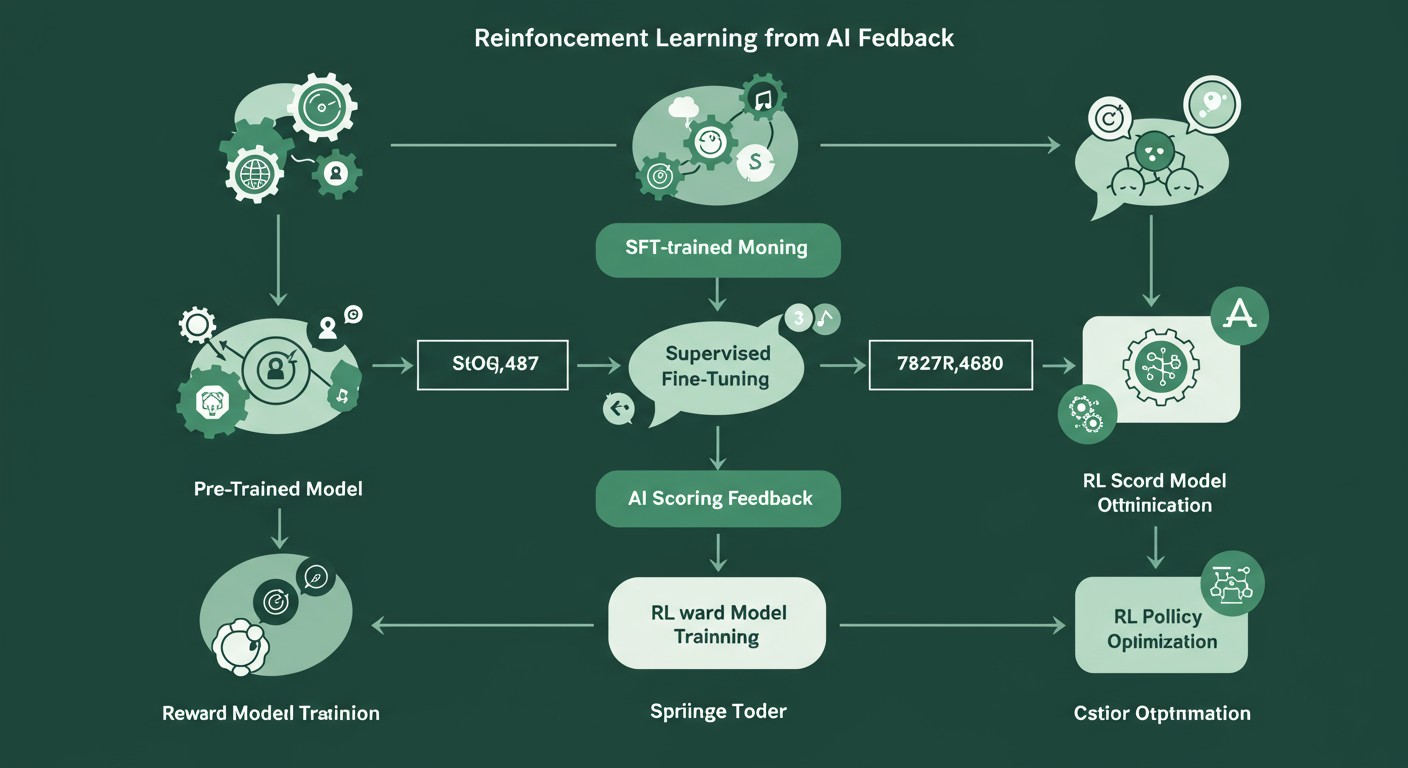
RLAIF的关键步骤包括:
- SFT(监督微调):同样从监督微调开始
- AI评分反馈:用更强大的AI模型(如GPT-4)对生成内容进行评分和反馈
- 奖励模型训练:基于AI反馈训练奖励模型
- 策略优化:使用训练好的奖励模型优化目标模型
三种对齐方法的对比
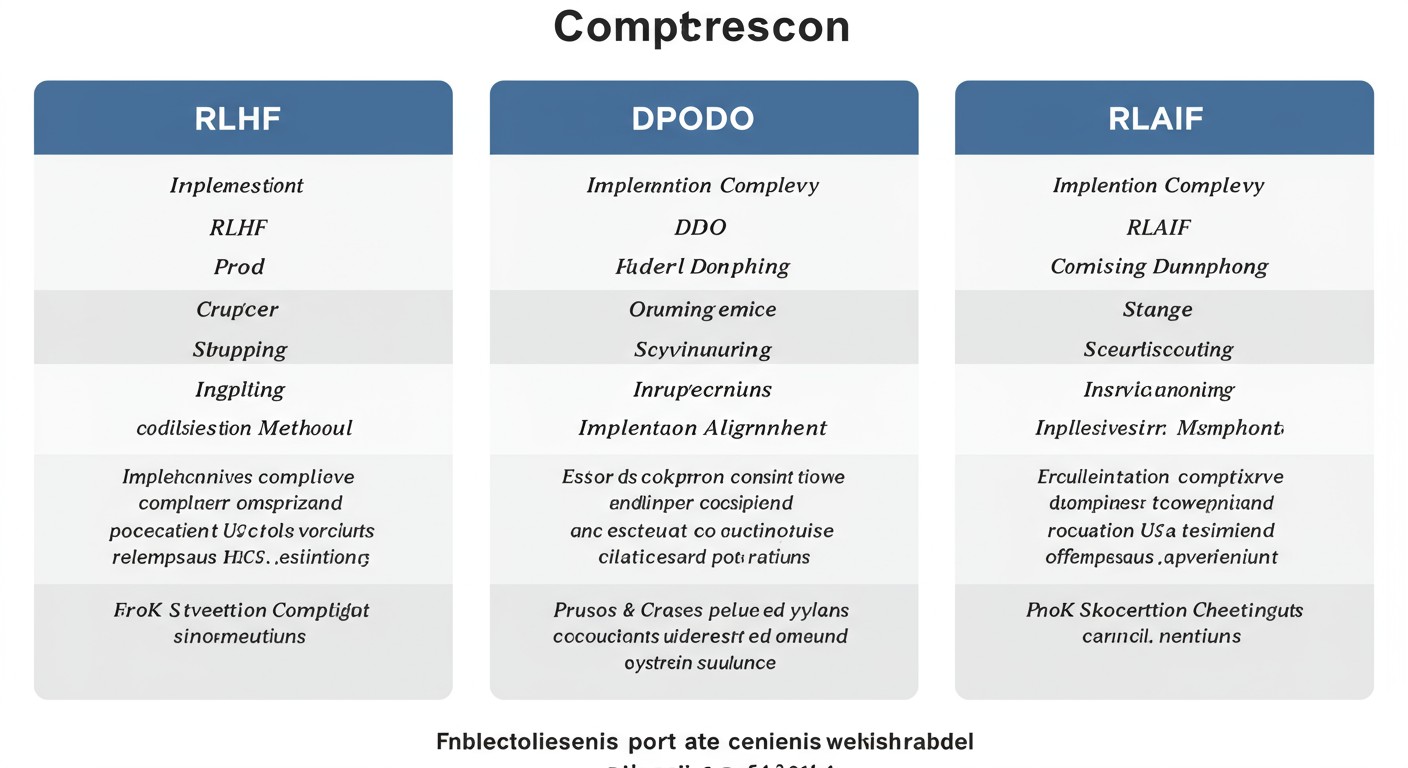
| 对齐方法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| RLHF |
|
|
企业级产品、安全敏感应用 |
| DPO |
|
|
资源受限环境、原型快速验证 |
| RLAIF |
|
|
大规模对齐、客观评估任务 |
构建轻量级实时反馈与自我纠错机制
传统对齐方法存在周期长、资源消耗大的问题。我们可以借鉴最新的研究成果,设计一种轻量级的实时反馈与自我纠错系统,让模型能够在运行过程中持续自我优化。
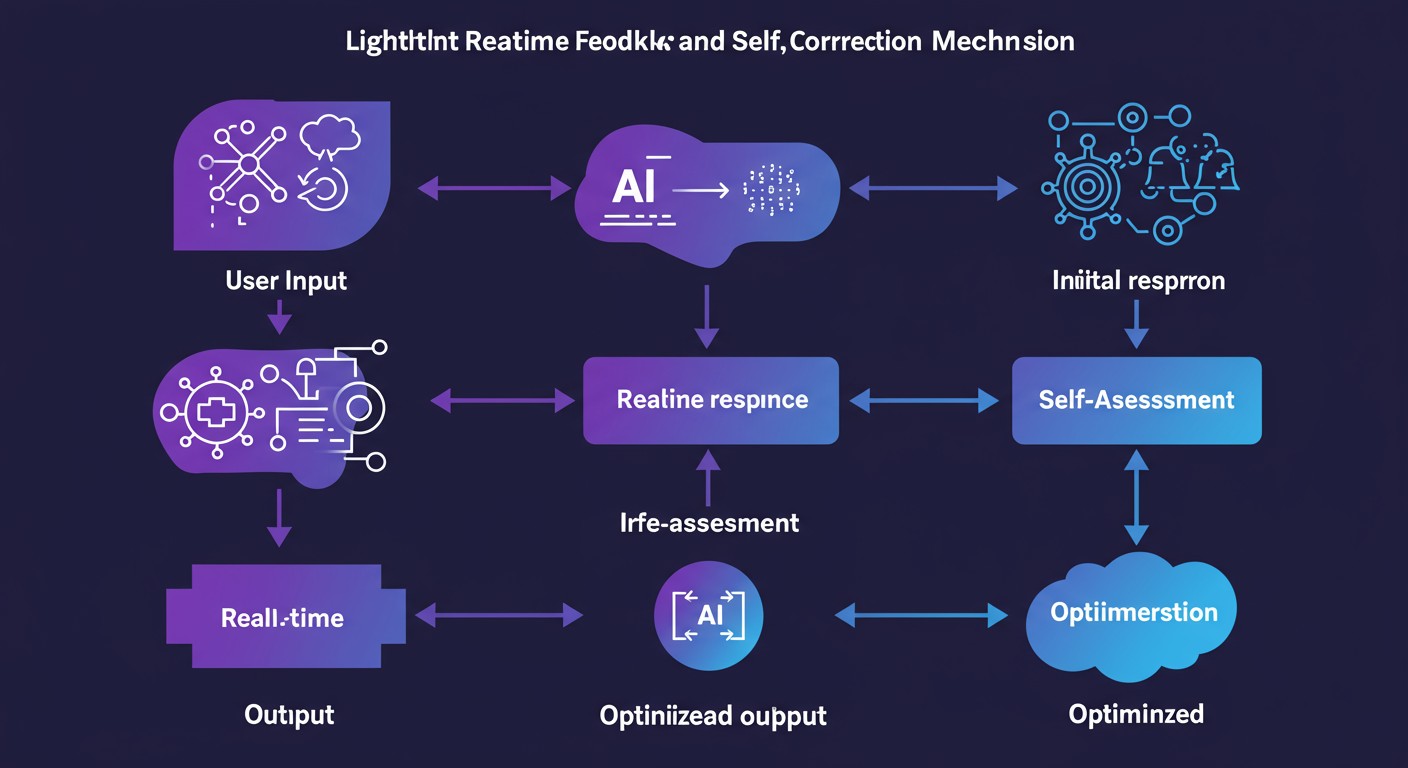
系统设计原则
- 即时评估:模型生成初步回答后,立即进行自我评估和检查
- 问题识别:检测潜在的事实错误、推理偏差、有害内容等
- 自主纠错:发现问题后自行修正,无需额外人工干预
- 闭环学习:将纠错过程作为新的训练信号,持续改进模型
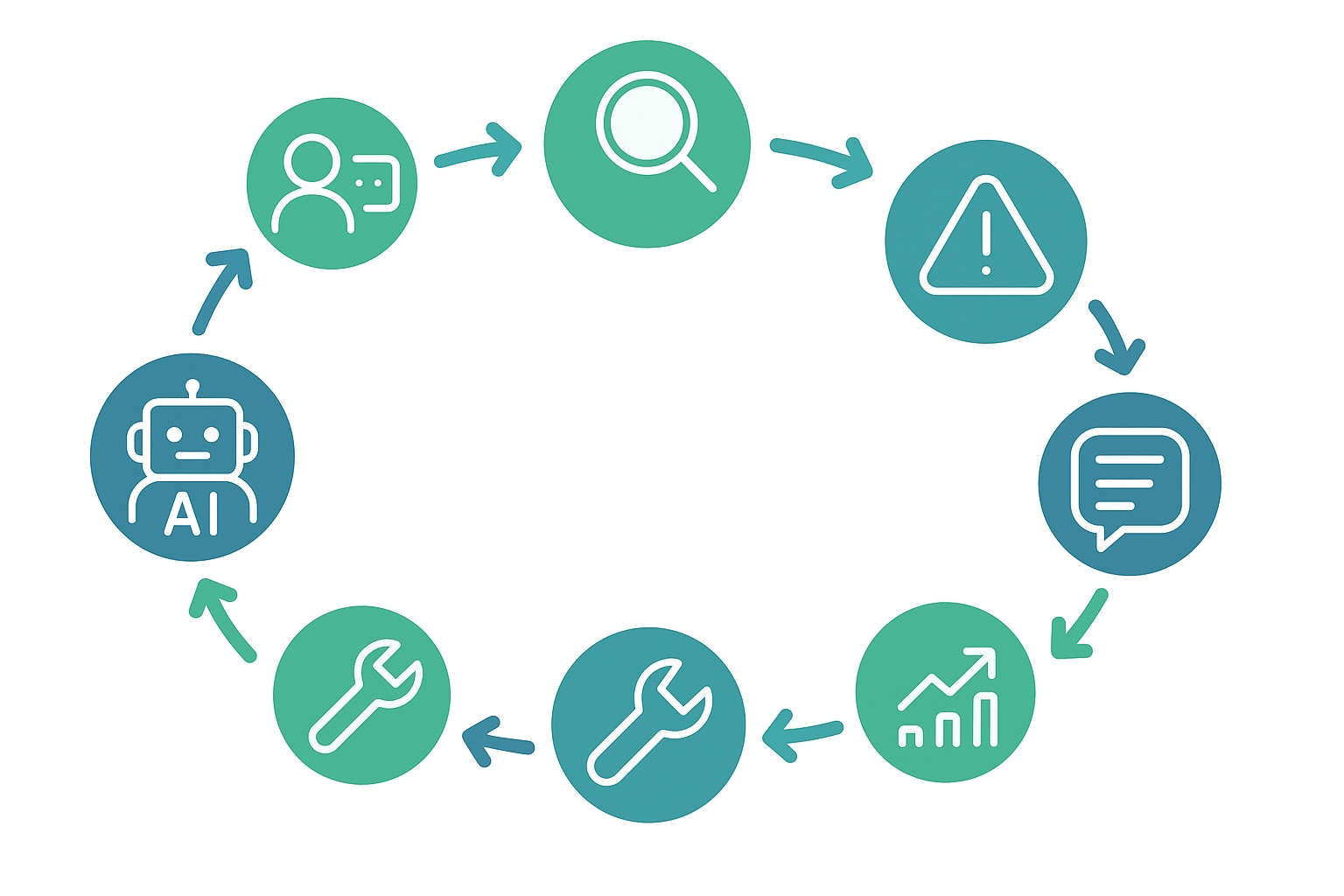
实现方案
1. 多模型协作架构
采用"生成-评估-改进"的三阶段架构,可以由同一模型承担不同角色,也可以使用不同模型协作完成:
- 生成器:负责初始答案生成
- 评估器:检查回答质量并给出评分反馈
- 优化器:根据评估结果改进初始答案
def lightweight_self_correction(prompt, model):
# 第一阶段:生成初始回答
initial_response = model.generate(prompt, role="generator")
# 第二阶段:自我评估
eval_prompt = f"""请评估以下回答的质量,并指出需要改进的地方:
问题: {prompt}
回答: {initial_response}
请从事实准确性、逻辑连贯性、完整性和有害内容四个维度进行评估。"""
evaluation = model.generate(eval_prompt, role="evaluator")
# 第三阶段:自我纠错
if "需要改进" in evaluation:
correction_prompt = f"""根据以下评估,请改进原始回答:
问题: {prompt}
原始回答: {initial_response}
评估: {evaluation}
请提供一个改进后的、更高质量的回答。"""
corrected_response = model.generate(correction_prompt, role="improver")
return corrected_response
else:
return initial_response2. 增强型可解释性评估
为了提高评估质量和可靠性,我们可以设计更精细化的评分维度:
多维度评估框架
- 事实准确性:回答中的信息是否与事实一致
- 逻辑连贯性:推理链是否清晰合理
- 回答完整性:是否全面解决了用户问题
- 安全性检查:是否含有有害、误导或不当内容
- 风格适配度:表达风格是否符合用户期望
评估器不仅给出分数,还需提供具体的问题分析和改进建议,帮助优化器进行有针对性的修正。
3. 动态适应与渐进式改进
通过在系统中引入记忆机制,让模型能够从过去的纠错经验中学习:
- 维护近期的纠错案例库,优先避免重复错误
- 根据用户反馈调整评估标准的权重,突出重要维度
- 追踪纠错成功率,自动调整纠错策略
实践经验分享
在一个客户服务AI项目中,我们实施了轻量级实时反馈机制后,误导性回答减少了约40%。特别有效的一个策略是将"减少确定性"纳入自我纠错流程——当模型对某些内容把握不足时,主动降低表述的确定性,加入恰当的限定词,这大幅降低了误导风险。我们也发现,保留少量人工反馈作为"校准信号",可以防止AI评估器与人类期望产生偏差。
系统集成与实践建议
模型对齐协议的技术实现
将上述对齐方法与实时反馈机制结合,构建完整的模型对齐协议:
- 初始对齐:使用RLHF/DPO进行基础模型对齐,确保基本安全和实用性
- 运行时对齐:部署轻量级实时反馈与自我纠错机制,处理边缘情况
- 持续优化:收集真实交互数据,定期使用RLAIF进行大规模再训练
// 模型对齐协议的JSON配置示例
{
"alignment_protocol": {
"initial_alignment": {
"method": "DPO", // 选择DPO作为初始对齐方法
"parameters": {
"beta": 0.1, // KL惩罚系数
"learning_rate": 1e-5,
"batch_size": 64
},
"data_source": "human_preference_dataset",
"evaluation_metrics": ["helpfulness", "harmlessness", "honesty"]
},
"runtime_alignment": {
"method": "self_correction",
"evaluation_dimensions": [
{"name": "factuality", "weight": 0.3},
{"name": "coherence", "weight": 0.2},
{"name": "completeness", "weight": 0.2},
{"name": "safety", "weight": 0.3}
],
"correction_threshold": 0.7, // 低于此分数触发自我纠错
"max_correction_iterations": 2 // 最多尝试纠错的次数
},
"continuous_improvement": {
"method": "RLAIF",
"update_frequency": "weekly",
"feedback_model": "gpt-4",
"data_collection": {
"sample_rate": 0.05, // 随机抽样5%的交互记录
"user_feedback_integration": true
}
}
}
}实践中的经验教训
关键注意事项
- 防止循环自评:设置最大纠错次数,避免无限循环
- 多样化测试:使用多样化的测试集评估对齐效果
- 渐进式部署:从低风险场景开始,逐步扩展到核心功能
- 人机协作:保留人类监督环节,特别是在高风险决策中
一个平衡的方案是将90%的常规场景交给轻量级自动机制处理,保留10%的复杂或高风险场景为人工监督,这样既提高了效率,又保障了系统的整体安全性。
未来展望与挑战
随着AI技术的快速发展,模型对齐领域仍面临诸多挑战和机遇:
挑战
- 价值多元性:如何在不同文化背景下定义"对齐"标准
- 评估困难:缺乏统一的对齐质量评估框架
- 模型欺骗:更复杂的模型可能学会"表面对齐"但内在未对齐
- 计算效率:如何在资源有限条件下实现高质量对齐
未来方向
- 自我监督对齐:模型自主发现并修正价值观偏差
- 跨模态对齐:扩展对齐技术到多模态AI系统
- 个性化对齐:根据不同用户群体调整对齐参数
- 强度可控对齐:灵活平衡创造力与安全性的动态对齐机制
结语
模型对齐是AI安全与伦理的基础,也是实现真正有用AI系统的关键。通过结合RLHF、DPO、RLAIF等先进对齐方法,并引入轻量级实时反馈与自我纠错机制,我们可以构建更加安全、可靠、符合人类期望的AI系统。
在实践中,没有一种对齐方法是万能的。根据应用场景、资源限制和安全要求的不同,灵活选择和组合各种对齐技术,才能达到最佳效果。更重要的是,保持开放的态度,随着技术的发展不断迭代和完善我们的对齐方法。
最终,我们的目标是构建既体现技术先进性,又充分尊重人类价值观的AI系统,让技术真正服务于人类的福祉。
参考资料
- Wang, Z., et al. (2024). A comprehensive survey of LLM alignment techniques: RLHF, RLAIF, PPO, DPO and more. arXiv preprint.
- Guo, S., et al. (2024). Direct language model alignment from online AI feedback. arXiv preprint.
- Anthropic. (2023). Constitutional AI: Harmlessness from AI Feedback.
- OpenAI. (2023). GPT-4 Technical Report.
- Rafailov, R., et al. (2023). Direct Preference Optimization: Your Language Model is Secretly a Reward Model. NeurIPS.